Reference image
to viral AI video.
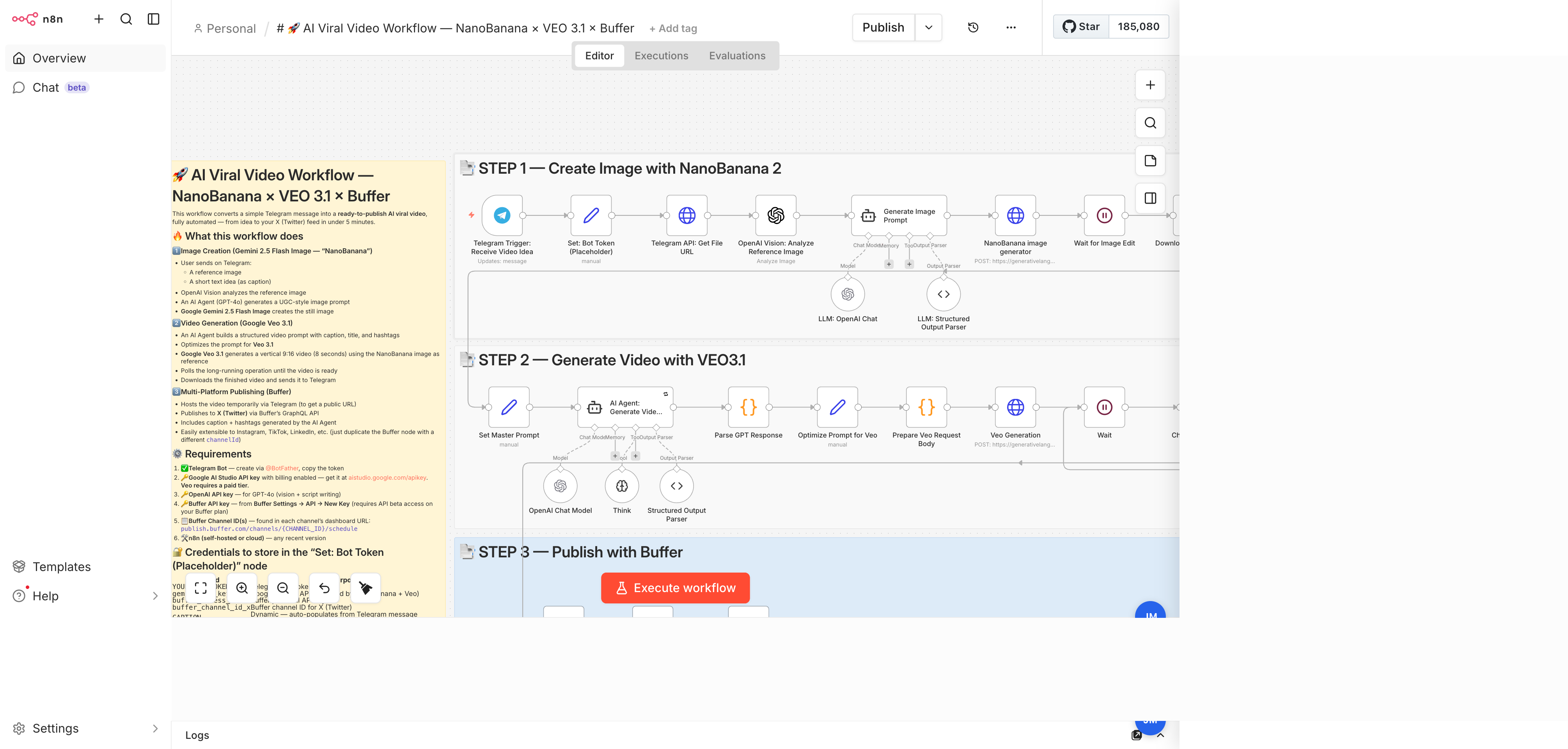
A Telegram-triggered n8n workflow that turns a reference image plus a short caption into a branded, 9:16 AI-generated video — published straight to X (Twitter) via Buffer. Image generation by Google Gemini 2.5 Flash Image ("NanoBanana"), video generation by Google Veo 3.1, script writing by GPT-4.1-mini. End-to-end run time: under 5 minutes.